With the growth of the internet, the number of options people have for everything from watching videos, to buying clothes has increased dramatically. Having potentially thousands of options, how are we to find and choose the best options for us?
Many internet companies have provided us tools to help us navigate these seemingly infinite number of choices.
For example, when you visit a product page on an ecommerce site, you may have noticed a section of the page that suggests other products you might like based on things you have purchased in the past. Perhaps you have received a push notification on your mobile phone recommending a video to watch. The closer you look, the more likely you are to find all sorts of recommendations being made in the websites and mobile apps you use.
All these tools are powered by recommender systems. Recommender systems are algorithms that use data about products and users’ preferences to make recommendations to users about the best options to choose from a set of options.
In this blog, we will learn about the properties of recommender systems, the ways they differ from traditional supervised learning, and the different types of recommender systems.
Recommender Systems v/s Supervised Learning
You may be wondering how recommender systems differ from traditional supervised learning techniques. In general, recommender systems do often utilize machine learning techniques.
So what is the difference between the two terms?
The difference is not in technique, but in purpose. Recommender systems are built to address problems of determining the best action for a user to take given a set of options. Supervised learning is generally used to describe machine learning to predict outcomes.
Let’s take the example of an E-Commerce website selling shoes. If the website built a machine learning model that was designed to determine how much each user would like each shoe, that model would be considered a recommender system.
However, if the purpose of the machine learning model is built to determine how many shoes the site would sell next month, that would be considered just an application of supervised learning.
Recommender systems also differ from traditional supervised learning in the specific properties are important for measuring their performance, as we shall see in the following section.
Properties of Good Recommender Systems
When considering the performance of a recommender system, there are a couple of different dimensions we should consider:

- Relevance: When a recommender system makes a recommendation, it should be relevant to the user. More specifically, these recommendations should be ones the user would likely rate highly . For example, a female user who only looks at and buys women’s shoes on an ecommerce website should generally only receive recommendations for women’s shoes. For many data practitioners, this is the most obvious and important property to optimize. However, it is critical to understand this is not the only important property of a recommender system.
- Novelty: Recommender systems should be ideally making recommendations the user has not seen before. For example, a recommender system that consistently recommends only the most popular women’s shoes to a female user may be considered a poor recommender system.
- Serendipity: Good recommender systems generally make recommendations that are somewhat unexpected. These sorts of recommendations (assuming they are relevant) can often delight users. Going back to our shoe ecommerce site example, a user that often purchases running shoes might get recommended sandals that are good for running from a serendipitous recommender system.
- Recommendation Diversity: Recommender systems that recommend many different types of items are more likely to have at least one item liked by the user. Looking at our shoe store site example, a recommender system that suggests to users not only shoes, but socks and shoe polish may be preferable to one that only recommends shoes.
- Technical Complexity: Recommender systems may often consist of many complex algorithms and parts. As a result, these systems require maintenance and some level of interpretability by technical staff. Therefore, recommender systems that are less complex and easier to understand are preferable from a cost and risk perspective.
Types of Recommender Systems
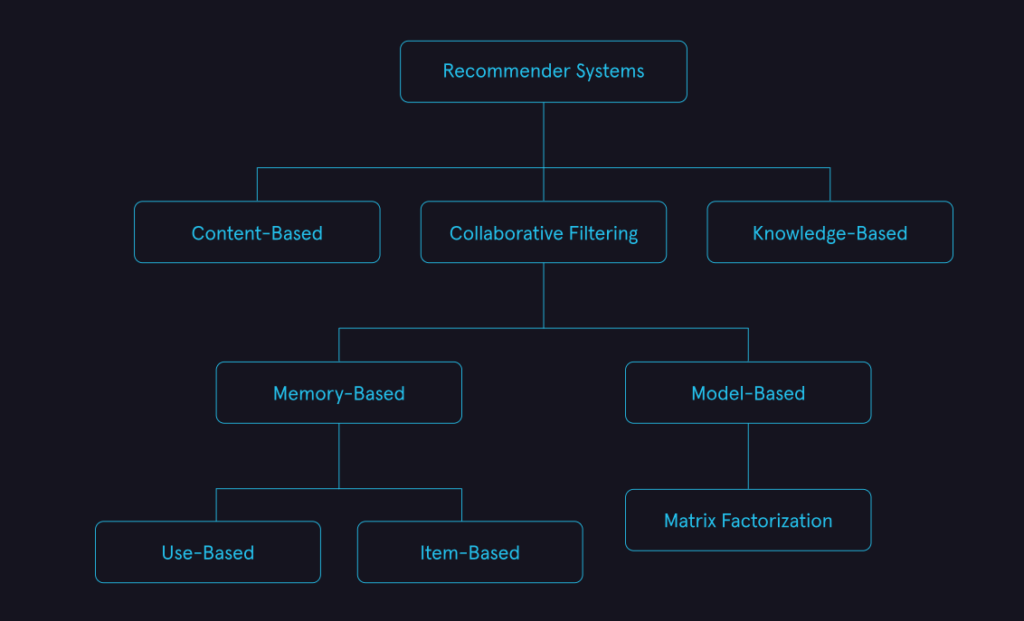
- Recommender systems can generally be classified into one of three different groups depending on the algorithmic approach they take to make recommendations:
- Collaborative Filtering: Collaborative filtering is a recommender system technique that makes recommendations for a target user by using ratings information from other users. The driving principle behind collaborative filtering is that users that have similar ratings for items have similar tastes.
- Content-based Filtering: Content-based Filtering is a recommender system technique that uses data about user preferences and attributes of items to model the likelihood a given user will like a specific item. This type of recommender systems tends to look more like the traditional machine learning models used in supervised learning.
- Knowledge-Based: Knowledge-based recommender systems are a class of recommender systems used when there is not a lot of data available. Rules are explicitly programmed based on user preferences and domain knowledge. While an important class of recommender systems, we will not be discussing them in detail in this module.
- We’re primarily going to focus on collaborative filtering in the course of this module.
Ratings Matrix: Representing User Preferences
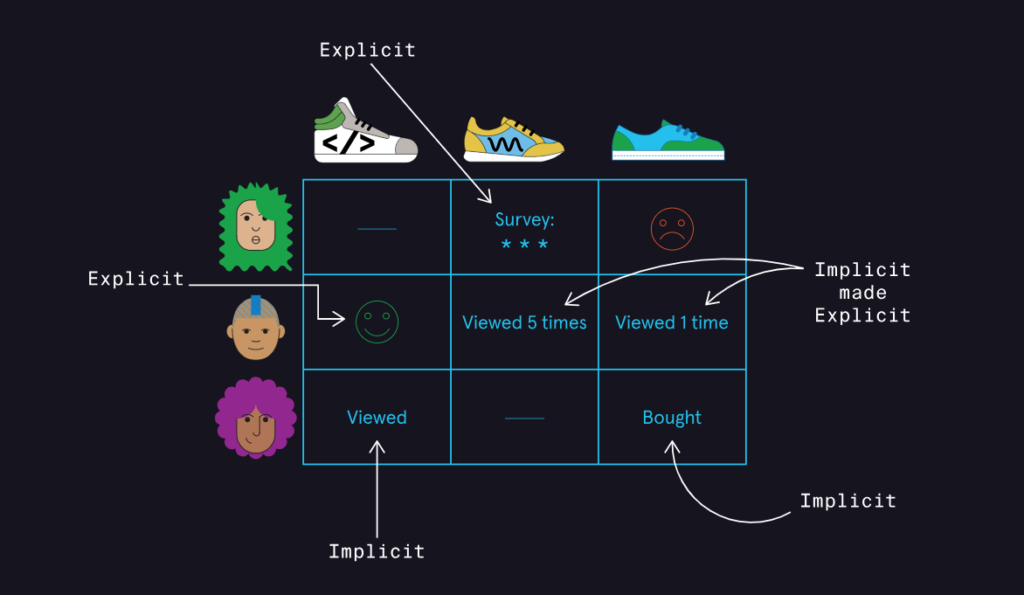
The first step in building a recommender system is to have a mathematical representation of data relating to user’s preferences. Often, the representation used is a matrix of numbers called a ratings matrix, where each row represents a user, each column represents an item, and the intersection of a row and a column contains the rating for an item given by a user. Ratings inside of a ratings matrix can generally be represented as either explicit ratings or implicit ratings.
Explicit ratings involve using the ratings given by users for items they have rated. Items that are not rated by users are left blank. Often they are normalized to help model performance. The major downside of this representation is explicit data may be scarce. Often, users skip rating items in an application. Often, rating data is not available at all.
On the other hand, implicit ratings do not require users to submit ratings. Instead, user events on the app or website are viewed as endorsements of an item. For example, purchasing an item on an E-commerce website could be viewed as an endorsement of an item. Any item that a user purchases could then be represented as a 1 in a ratings matrix, and anything they do not purchase can be represented as a 0. The main advantage of implicit ratings is that data is much more readily available. The major downside is the data is not as granular as that of explicit ratings, and therefore recommendations can degrade accordingly.
And sometimes an implicit rating can be converted into an explicit rating according to the data scientist’s discrtion. For instance a user may have listened to one song fifty times on an audio streaming service and another one, only five times. There is relative information here as regards the user’s preference on two items that can be converted to explicit ratings.
Collaborative Filtering
In the previous exercise, we introduced collaborative filtering. However collaborative filtering can be further classified into two major subclasses: memory-based methods (also called neighborhood-based methods) and model-based methods.
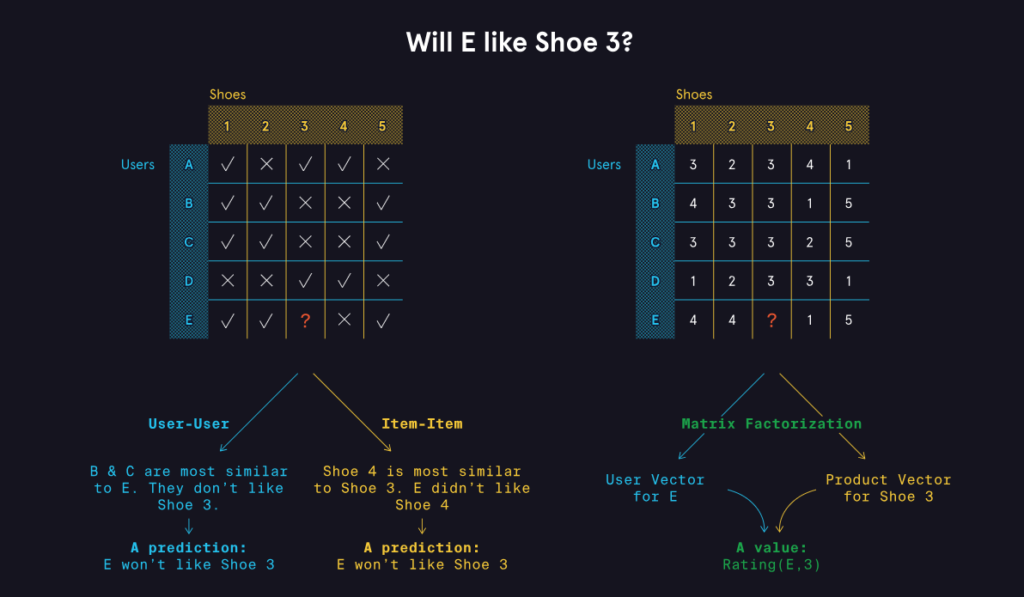
Memory-based methods work through the concept of similarity. Fundamentally, memory-based methods work in one of two ways:
- The algorithm finds similar users to the target users, and recommends items those similar users liked. This approach is known as user-user collaborative filtering.
- The algorithm finds similar items to ones the target user liked by measuring the similarity of how users rated items. This approach is known as item-item collaborative filtering.
In contrast, model-based methods work by building models that attempt to predict a rating for a user-item pair by using ratings as features. One particular method that is often used in practice is matrix factorization. This method models the user-item ratings matrix as the product of a set of users vector and product vectors. The rating of any user-item pair can then be predicted by multiplying the relevant user vector by the relevant product vector.
After creating a ratings matrix, various data transformations may be performed on the ratings matrix. These transformations are done generally to improve model performance, similar to how normalizing features in a machine learning model can help improve performance.
One such transformation is ratings normalization. Ratings normalization is a technique where the value of each rating for a given row is adjusted based on the statistical properties of that row. The primary reason this transformation is done is because different users may have different approaches to rating something. For example, some users may give a 5-star rating to any positive experience they have. Other users may be more selective, and only give 5 star ratings very rarely. Ratings normalization provides a way to control for these differences.
Summary
In this lesson, we learned about recommender systems. We learned about how they compare to traditional supervised learning and what the properties of good recommender systems. We also discussed the different types of recommender systems, as well as how we can transform data for use in recommender systems. We are now ready to learn how we can use Python to implement and build recommender systems.
Related Posts
Understanding SQL Data Types & Table Constraints
Welcome back! 👋In the last lesson, we created our first database and tables.…
Sorting, Grouping, and Aggregating Data in SQL
Welcome back! 👋So far, we’ve learned how to: Retrieve data…

Advanced JOINs – Self Joins, Multiple Joins, and Anti/Semi Joins
Welcome back! 👋In the last lesson, we learned the basics…