6 broad categories related to the For Databricks Certified Data Engineer Professional exam topics, which are:
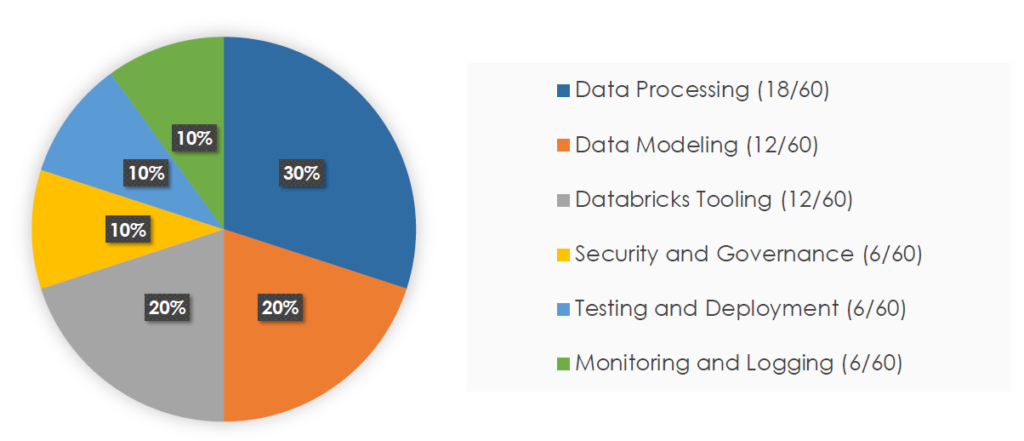
- Modeling Data Management Solutions in Databricks Lakehouse.
- Data processing using Spark and Delta Lake APIs.
- Databricks Tooling
- Security and Governance
- Testing and Deployment.
- And lastly, Monitoring and Logging.
Having the Data Engineer Associate certification from Databricks is not a prerequisite to appear for the Professional-level certification exam.
However, this exam assumes that you have the skills of a data engineer associate on Databricks platform.
The source code is available here on GitHub (https://github.com/datatorials/Databricks-Certified-Data-Engineer-Professional.git), and we can easily clone this repository in Databricks Workspace using Databricks Git folders.
Let us copy the repository URL and switch to our Databricks workspace.
We will use Databricks Free Edition
To clone a repository, go
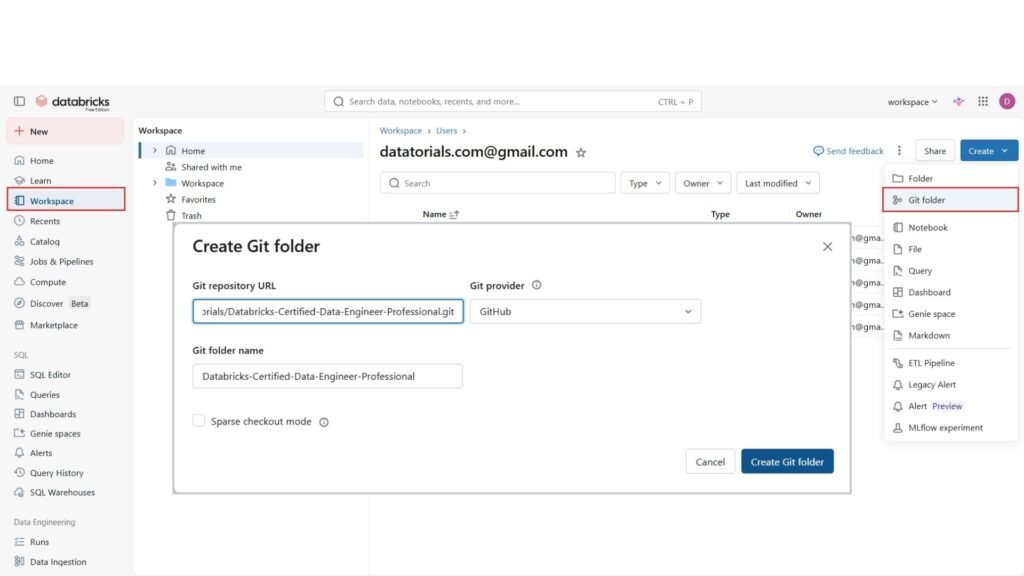
- First to the “Workspace” tab in the left sidebar, and now on the right click the Create button and choose “Git folder“. Git folders are special types of folders that provide source control for your data projects by integrating with Git providers.
- Paste here the URL of our git repository and as you can see, the git provider will be automatically filled and also the folder name. Now click “Create Git folder”.
- Here are the notebooks of our course.
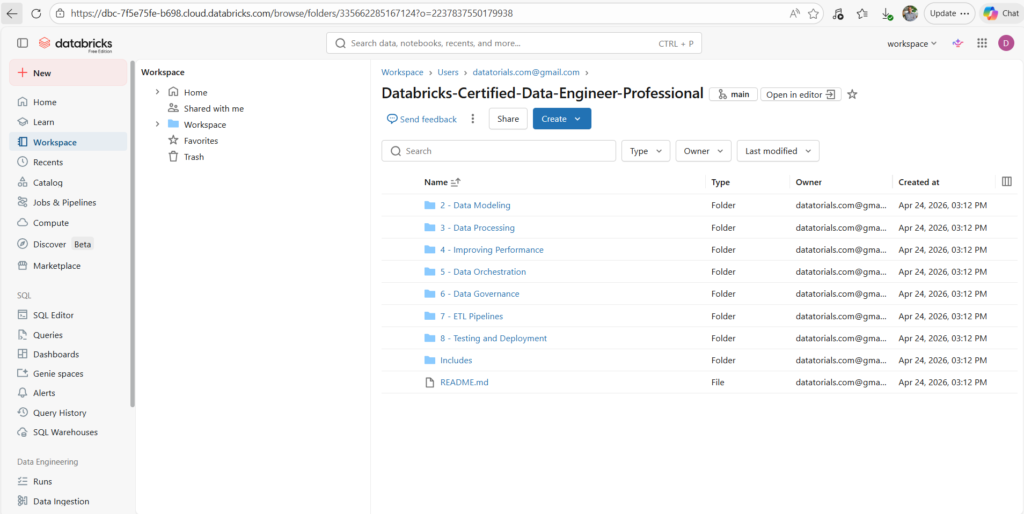
we will work on a bookstore dataset.
Here is the schema of this dataset.
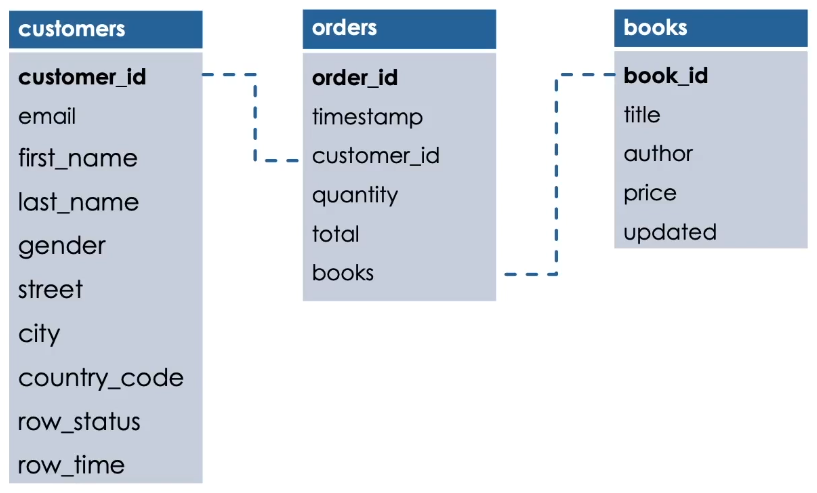
There are three tables.
Customers, orders and books.
Here, we illustrate the architectural diagram we are going to build throughout the course.
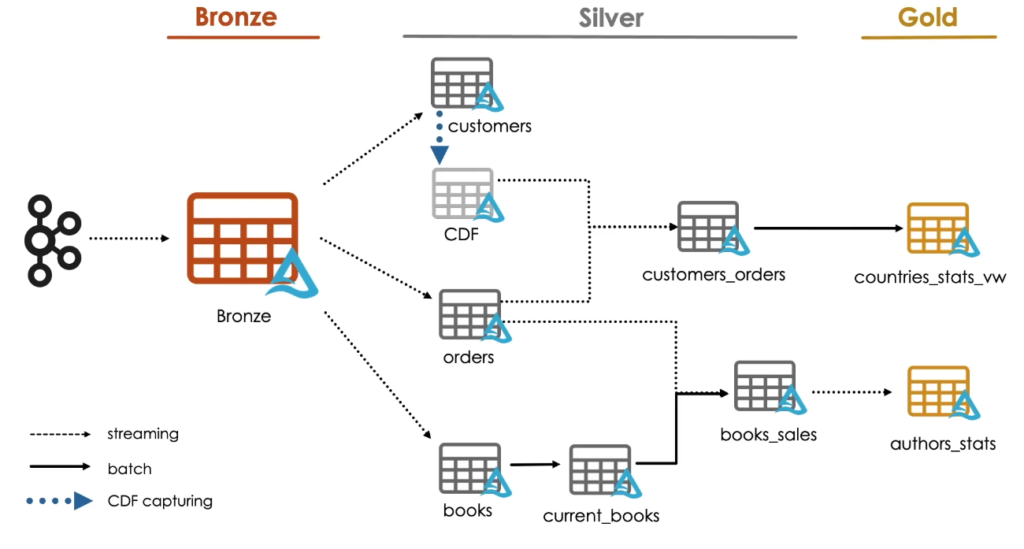
It’s a Multi-Hop or Medallion architecture that consists of three layers:
Bronze, Silver and Gold.
We will improve the structure and the quality of data as it flows through each layer of this architecture.
We start by receiving streaming data from a Kafka source and store it in what we call a Multiplex Bronze table.
We will see the Multiplex ingestion pattern in details in the next module.
Next, we will spend most of our time in the next two modules in the Silver layer, So we get more refined view of our data.
We will see how to stream data from Multiplex Bronze table into the different silver tables. First, we start by processing the orders table data where we will explain important concepts like Quality Enforcement and Streaming Deduplication.
Next, we will introduce the concept of Slowly Changing Dimensions, and we will see how to create the books table as a slowly changing dimension of Type 2. From this table, We will see how to create a new Silver table with batch overwrite logic.
We will then go ahead and process Change Data Capture or CDC feed to create our customers Silver table.
Following this, we will introduce a new feature built into Delta Lake called CDF, and we will see how to use it to propagate incremental changes to downstream tables in our architecture.
Once we are done processing these tables, we will move on to understand how streaming joins can be performed between them. We will see first how Stream-Stream joins work in order to join two streams of data together. Then, we will see how Stream-Static joins work in Delta Lake in order to join a stream with a static dataset.
Finally, we are going to learn how stored views and materialized Gold tables can be created in Databricks.
We will see many other advanced topics during the course, like Security and Governance, Performance Improvement and much more.