We are going to give a quick overview of how stored views and materialized views can be created in Databricks.
For this demo, we will create our two gold layer entities.
We will start by creating a view in the gold layer against our silver table customers_orders.
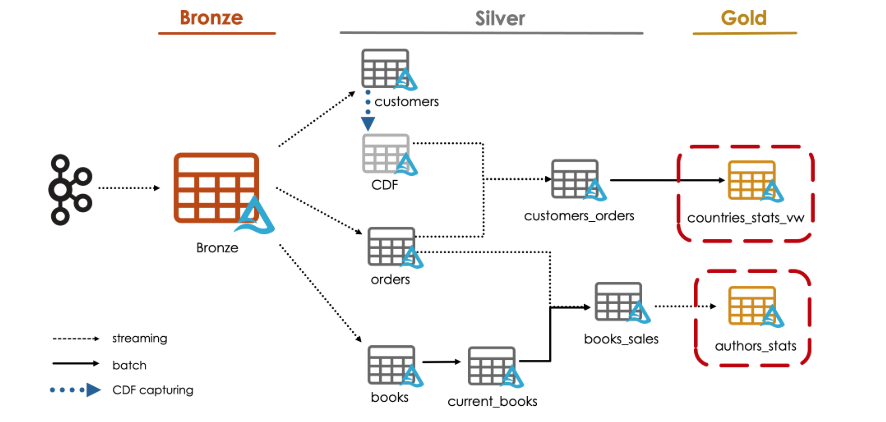
Our view will simply contain some aggregations for daily sales per country.
Here we are calculating orders count and books counts per country and order day.
Let us run this to create the view.
%sql
CREATE VIEW IF NOT EXISTS countries_stats_vw AS (
SELECT country, date_trunc("DD", order_timestamp) order_date, count(order_id) orders_count, sum(quantity) books_count
FROM customers_orders
GROUP BY country, date_trunc("DD", order_timestamp)
)Remember a view is nothing but a SQL query against tables.
If you have a complex query with joins and subqueries each time you query the view, delta have to scan and join files from multiple tables, which would be really costly.
Okay, now let us query this view.
%sql
SELECT *
FROM countries_stats_vw
WHERE country = "France"Let us rerun this query and see how fast it is.
Even if you have a view with complex logic, re-executing the view will be super fast on the currently active cluster.
In fact, to save costs Databricks uses a feature called Delta Caching.
So subsequent execution of queries will use cached results.
However, this result is not guaranteed to be persisted and is only cached for the currently active cluster.
In a traditional databases usually you can control cost associated with materializing results using materialized views.
In Databricks the concept of a materialized view most closely maps to that of a gold table.
Gold tables help to cut down the potential cost and latency associated with complex ad-hoc queries.
Let us now create the gold table presented earlier in our architecture diagram.
from pyspark.sql import functions as F
query = (spark.readStream
.table("books_sales")
.withWatermark("order_timestamp", "10 minutes")
.groupBy(
F.window("order_timestamp", "5 minutes").alias("time"),
"author")
.agg(
F.count("order_id").alias("orders_count"),
F.avg("quantity").alias ("avg_quantity"))
.writeStream
.option("checkpointLocation", f"{bookstore.checkpoint_path}/authors_stats")
.trigger(availableNow=True)
.table("authors_stats")
)
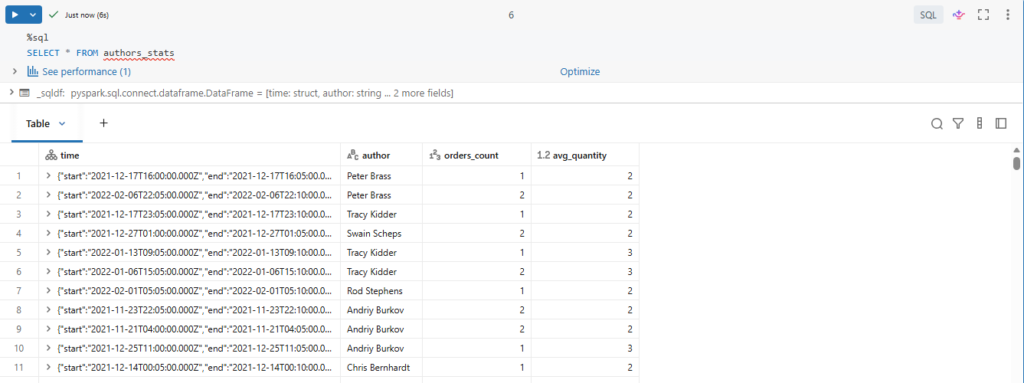
query.awaitTermination()This table Stores Summary statistic of sales per author.
It calculates the orders count and the average quantity per author and per order_timestamp for each non-overlapping five minutes interval.
Furthermore, similar to streaming deduplication we automatically handle late, out-of-order data, and limit the state using watermarks.
Here we define a watermark of ten minutes during which incremental state information is maintained for late arriving data.
.withWatermark(“order_timestamp”, “10 minutes”)
Let us now review the data written in our new gold table.
%sql
SELECT * FROM authors_statsHere are our author statistics.